
When every second of downtime costs thousands
It started with a straightforward feature request. NS1 customers using secondary DNS providers alongside NS1 as their primary needed to know when zone transfers failed. This sounds like a small notification problem, until you consider that the entire purpose of a secondary DNS provider is redundancy.
The outage that shook the global economy
Few events illustrate the importance of DNS redundancy better than the major AWS outage in October 2025. AWS powers over 90% of Fortune 100 companies along with most Fortune 500 businesses, including names like Apple, Netflix, and McDonald's. The disruption lasted fifteen hours, affected over a thousand companies, and cost the global economy more than one billion dollars — roughly $75 million for every hour it persisted.

A liability hiding in plain sight
The need for zone transfer failure alerts exposed a deeper gap in the product. Customers had no way of configuring alerts for critical events. NS1's platform was largely built around a "set it and forget it" philosophy, customers configured their DNS, and the product handled the rest quietly in the background. That design worked well for day-to-day operations, but it left a blind spot for the moments when things went wrong and silence became a liability.
Without a native alerting system, customers had no way to know about failures until the downstream consequences surfaced. A degraded service, a customer complaint, an outage that could have been contained if someone had been notified fifteen minutes earlier. For the 850+ customers relying on NS1 to keep their infrastructure resilient, that gap between failure and awareness was an unacceptable risk.
Those who made it happen
Mohammed Mahmoud – Sr. Product Manager
Tomás Ó hAodha – Engineering Manager
Jonathan Rice Madden – Product Program Manager
Da Liu – Front-End Lead
Shane Kerr – Back-End Lead
Erin Pelkey – Content Strategist
Tony Hartonias – Product Designer
Core challenges and constraints
Configuration hub > monitoring dashboard
Since NS1's users didn't spend extended time in the product, showing alerts within the portal would mean no one saw them when it mattered most. Instead, we designed around outgoing alerts — notifications pushed to wherever customers were already paying attention. That reframing shaped the entire experience. The Alerts Center became a configuration hub rather than a monitoring dashboard, giving users the tools to define what they cared about and where they wanted to hear about it.
Designing for future expansion
The MVP was scoped to zone transfer failure alerts, with the architecture designed to support additional alert types in future releases. The constraint was building a system flexible enough to grow while shipping something focused enough to deliver immediate value.
Legacy architecture and technical dependencies
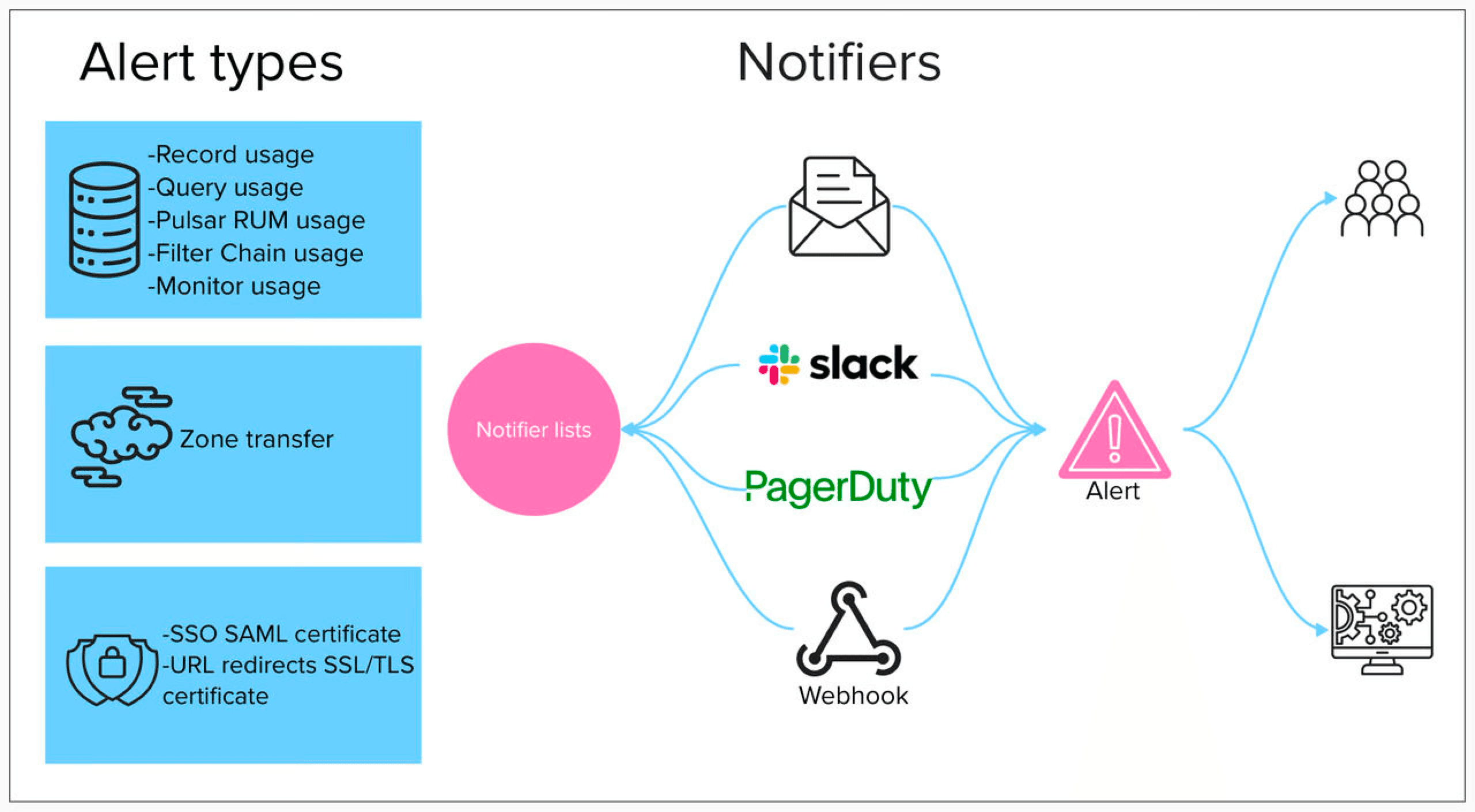
The most significant design constraint came from the existing architecture. Alerting destinations relied on a system of Notifiers and Notifier Lists — where individual notifiers represented specific endpoints like a Slack channel, email address, PagerDuty key, or webhook URL, and notifier lists served as the containers that grouped them.
The complication was that notifiers couldn't exist outside of a notifier list. So when a user wanted to create an alert, they either had to select an existing notifier list that already contained the right destinations, or build one from scratch — creating the list first, then adding individual notifiers to it, even if those exact same notifiers already existed in other lists.
The result was a multi-step configuration process that felt unnecessarily long and fragile for what should have been a simple action: tell me when something breaks, and tell me here.
The key moves
Designing for where users actually are
We designed the configuration flow around outgoing destinations: webhook integrations for teams piping alerts into third-party monitoring dashboards, Slack integrations for teams that used channels as their operational nerve center, and email for those who needed a reliable fallback.
This flexibility meant the Alerts Center fit into existing workflows rather than asking teams to adopt a new one. A small team using Slack for everything and an enterprise with a sophisticated observability stack could both get value from the same system.

Taming architectural complexity with tearsheets
The Notifier and Notifier List dependency was the biggest design challenge. Users needed to configure multiple layers of dependencies just to set up a single alert, and the architecture couldn't be changed for the MVP.
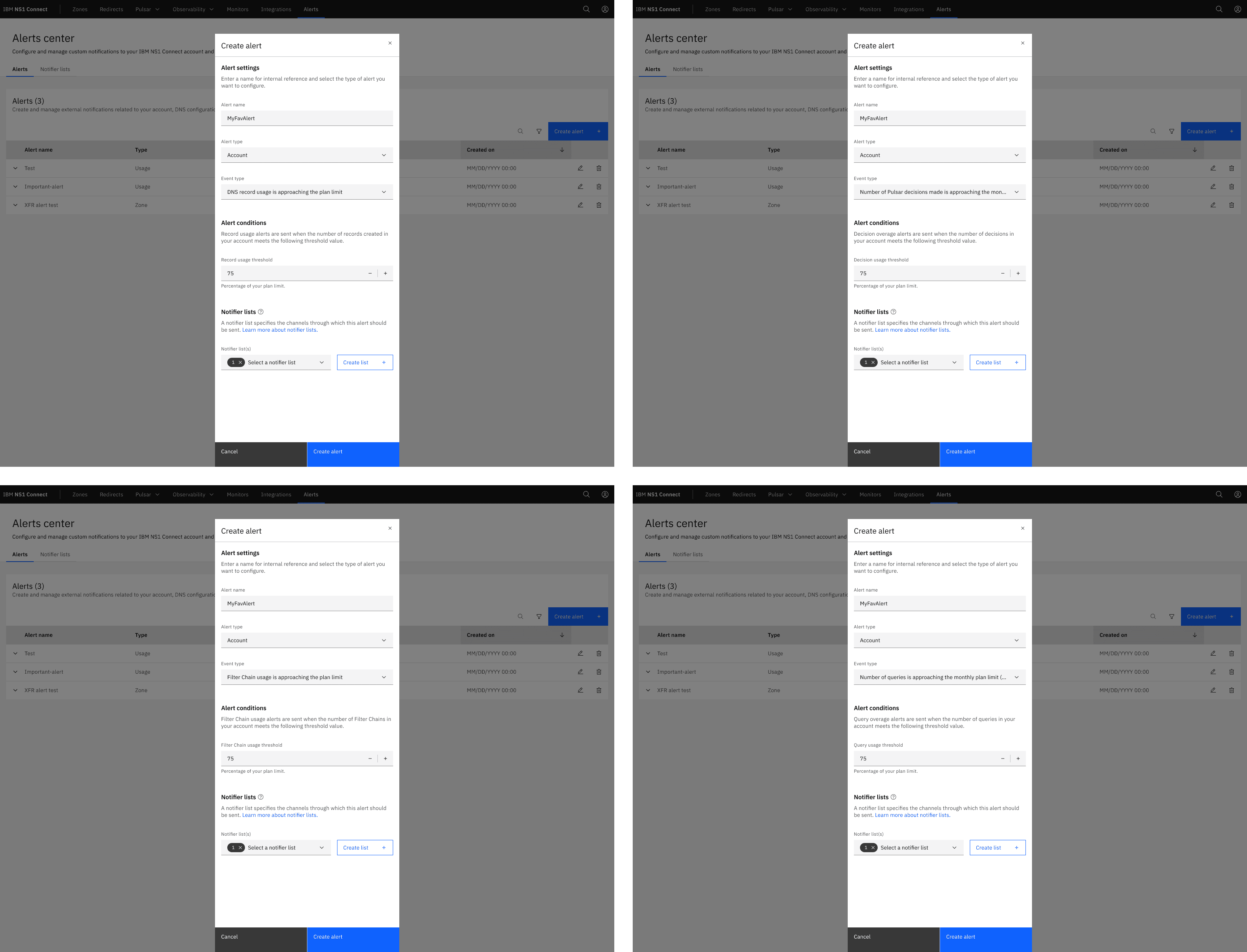
We used Carbon's tearsheet pattern to keep users in context throughout the entire flow. Instead of bouncing users between separate pages to create notifier lists and individual notifiers, tearsheets let them handle each dependency inline — define the alert type and conditions, create or select a notifier list, and add notifiers — all within a single, continuous interaction.
The layered panels made the multi-step process feel contained and logical rather than scattered. What could have been a frustrating back-and-forth became a guided flow that respected the architectural reality without exposing its complexity to the user.
Giving users ownership over the signal-to-noise ratio
Alerting systems fail when they notify users about everything or when users can't trust the signal. we designed the configuration experience so that users could specify exactly which events warranted notification and define their own thresholds and conditions.
By letting users set the terms themselves, every alert that came through carried weight because the user had explicitly decided it mattered. The configuration flow was designed to be approachable enough for quick setup while offering the granularity that users expected.
Accommodating for future alert types
Zone transfer failures were the right starting point — high severity, clear use case, immediate customer need — but the Alerts Center had to be architected for what came next. I designed the information architecture and interaction patterns to accommodate future alert types without requiring a structural redesign.
The configuration flow, destination management, and event selection interfaces were all built as extensible patterns. When new alert types were added in subsequent releases, they slotted into the existing framework cleanly, which meant the experience scaled without fragmenting.
The impact
The Alerts Center gave NS1 customers the ability to detect and respond to critical DNS events in real time for the first time. By pushing notifications to the tools teams were already using — Slack, webhooks, email — the design collapsed the gap between failure and awareness, reducing mean time to incident recovery. In an industry where downtime averages $5 million per incident, even minutes saved during detection and triage translated to significant financial protection for customers.
The feature also shifted NS1's competitive positioning. Alerting moved from a gap in the product story to a native capability, and the webhook and Slack integrations meant NS1 played well with the broader monitoring ecosystem rather than competing against it. For customers, the Alerts Center turned a "set it and forget it" platform into one that actively had their back when it mattered most.
What I learned
Building on moving ground
Scale isn't just about technical performance, it's also about designing for the unknown. While engineers focus on handling thousands of concurrent users or events, designers have to think about a different kind of scale: How do we build something that can evolve without breaking?
This tension between building for today and designing for tomorrow creates an interesting paradox. We want to create robust, lasting experiences, but we also know that user needs, business requirements, and technology will inevitably change. It's like trying to build a house on shifting ground, you need a foundation that's solid enough to support what you're building today, but flexible enough to adapt when the landscape changes.
When designing the Alerts Center, I kept wrestling with the thought that no matter how much I tried to design a robust experience, there'd come a time when we would have to tear it all down and build it again from the ground up.